Entering specimen data
Page in Finnish: Näytedatan tallennus

Methods of data entry
Data can be entered into Kotka in two ways:
A) With an entry form/web form
Using the entry form is the easiest way to enter or edit few new specimens. There are five different forms for different specimens: Botanical, Zoological, Palaeontological, Accession (living garden accessions) and culture (microbial). The forms are quite similar, but have some form-specific fields. When entering data using a web form, the datatype is defined by the form used. Open an empty, new form from the menu: Specimens > Add... Kotka will validate the data upon saving. More information about using the web forms and their specialties compared to the Excel-import: Specimen web forms
b) With an Excel import sheet/template
Using Kotka import Excel sheet might be quicker way to record large amount of specimen data (hundreds of specimens or more). Download a template with the fields you need from Kotka, in the top menu bar under Tools → Excel generator. Then fill in your data, with identifiers and other mandatory fields (see below). Import the file into Kotka from Tools → Import. Kotka will validate the data and shows preview. If validation succeeds, you can proceed to save the data. More information about the Excel generator and the Excel templates and import. Excel can also be used for Excel exports and mass editing
Mandatory fields and validations
Mandatory fields
Specimens have only few mandatory fields, all else are optional. Mandatory fields are:
- Namespace ID and object identifier, used to create specimen identifier. More about Specimen Identifiers
- Collection the specimen belongs to. One specimen always belongs to one collection and collections are organised hierarchically. Mole about CollectionsAineistot
- Owner of record for the specimen. Organisation that owns the specimen and whose members can edit the specimen information.
- Record type/Record basis (preserved specimen, observation or such). In Kotka most often Preserved specimen for museum specimens. Chosen from a list of values.
- Country or higher geographical area. If there is absolutely no locality information and the specimen could have been collected anywhere, "Earth" can be entered to the Higher geography as a workaround.
Validations
Kotka validates (checks) the specimen data for errors before it can be saved. Validations are used both on the web forms and Excel import. Validation system has several “rules” for correct data. These rules are used to find different types of errors, such as missing mandatory data, incorrect values and incorrect data formats. Validation can result in two kinds of issues:
- Warnings, which indicate there is some kind of small problem with the data. For example, Kotka gives a warning if a collector's name is not in the recommended format "Lastname, Firstname". It is good to go through the warnings before saving, they are there to help you keep the data clean. After going through the warnings, and fixing those that are possible to fix, you can ignore the warnings and save the data, if it’s good enough for your purposes.
- Errors, which are more severe problems. For example, Kotka gives an error if there is a mandatory value missing. Errors prevent saving the data, in which case you have to check the problem, edit the data to fix the issue and try again.
All validation rules are documented in the data field list. If you wish to have more validation rules or some existing rules are causing problems, please contact Kotka administrators kotka(at)luomus.fi. New rules can be easily added. The purpose of these validations is to keep the data tidy and somewhat harmonised and help the user to notice errors in the data, without making the data entry too difficult or slow.
Hierarchical structure of the data model
Specimen information is entered in to Kotka to a hierarchical structure. Each specimen is roughly the same as a document and has one collecting event/gathering. That then has one or more units (specimens/observations), and each of these have zero or more identifications and type information. A unit can also have zero or more preparations/samples. It is easiest to perceive the structure on the web form than on the Excel templates. For garden accessions, there can be zero or more branches (puutarhasijoitus) below an accession, and zero or more events below each branch.
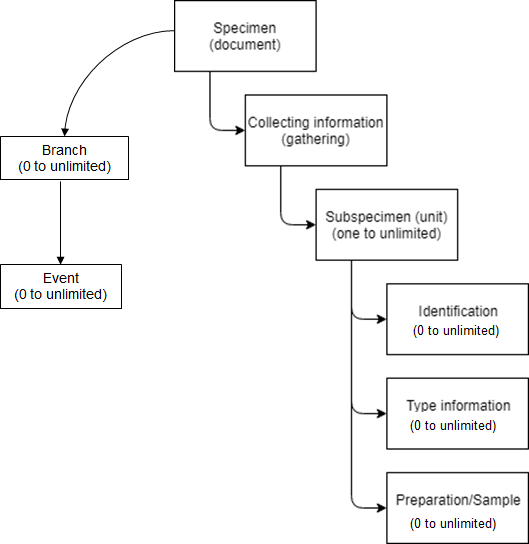
Specimen data model used by Kotka. Every specimen can have any number of sub-specimens/units (e.g. insects in a jar), and each of them any number of identifications, type information and preparations (morphological preparations, DNA extracts, tissue samples or such). More about the fields and data entry for each section below.
General guidelines for entering data
There are a few different types of fields in Kotka. Most are free-text fields. Some are dropdowns (pudotusvalikko), some multi-selects and in some you select the prefix and after that type in any text. Admins can easily add values to dropdowns. If you require new options, contact the admins kotka(at)luomus.fi.
Part of the fields are repeatable, for example Leg or Additional IDs. On the web forms, repeatable fields have a green and white + symbol next to them, and each collector for example, is typed to their own field. On Excel templates, repeatable information is separated using a semicolon ; (puolipiste). Use semicolon in Excel also for multi-select fields, like Record parts.

It is possible to customise the web forms, so that some fields are hidden. More information about this: Specimen web forms
Locality names can be entered using one of the old names or the latest name. You can for example choose to use the name of the time the specimen was collected. It is not necessary to for example change the name of the municipality Tammisaari to Raasepori (because of consolidation of municipalities), as Raasepori is less specific. For country names, a new country may be more specific than the old one, for example Czechoslovakia vs. The Czech Republic. In the future it will be possible to change names to the modern ones automatically if necessary (feature not in the pipeline yet).
Person names are recommended to be entered in the format "Lastname, Firstname" or "Lastname, Initials" to all fields. Semicolon (puolipiste) can be used to separate names in repeating and non-repeating fields.
Dates are recommended to be entered in the format dd.mm.yyyy, for example 24.6.2017.
Decimal symbol is point . not comma ,
Marking information unreliable
There are a few ways of marking information unreliable or uncertain in Kotka. Fields can be marked as unreliable by writing a question mark at the beginning of the field, e.g. "?Espoo". This cannot be done with those fields where only certain values are allowed. In these fields, select appropriately vague value and clarify in notes field, if necessary.
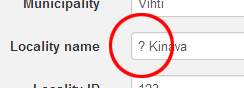
If the whole specimen record is unreliable, select Needs verification on Verification status -field. This field can also be used to mark those specimen records which need completion, e.g. identification, georeferencing or more data from external sources (e.g. notebooks).
Qualifiers can be used to express uncertainty in identifications, see Identification(s)above.
Verbatim fields and interpretations to the data
When digitizing old specimens, it is important to always record the original data from labels as it has been written, even if it seems to be erroneous. There are several verbatim fields which are meant for storing this original data. Interpretations of this data can then be recorded in other fields. This way no old data is lost in the interpretation process and it is always possible to go back to the original data, but interpreted/corrected data can still be used. Verbatim labels is for information as it appears on original labels, but other verbatim fields can be used for data from other original sources, too.
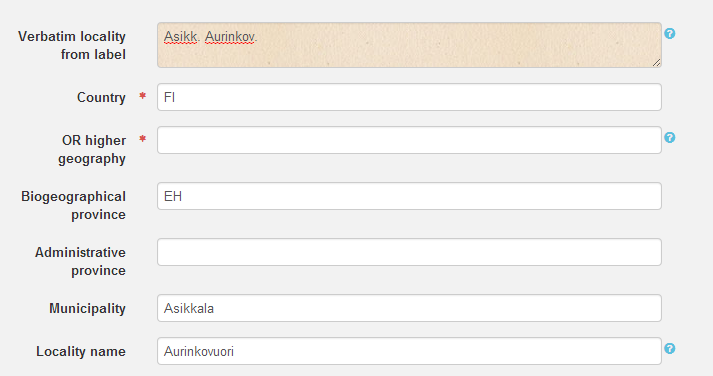
For example, if label describes the locality as “Asikk. Aurinkov.”, write this to Verbatim locality -field. Then interpret this to Municipality and Locality fields as “Asikkala” and “Aurinkovuori”, correspondingly.
Other method has been to write both original and interpreted data into a single field and separating interpretations with brackets (e.g. “Asikk. [Asikkala], Aurinkov. [Aurinkovuori]”). This is not recommended however, because using this kind of data automatically is difficult or impossible (e.g. analyzing, creating statistics or combining with other data). These kinds of interpretations can be entered only to verbatim and notes fields, not to the actual data fields. Also do not enter the same thing in different languages to one field. Missing and unclear letters can be replaced with a question mark ?. Keep in mind that it is difficult to make searches to and statistics based on information written like this. For example "Helsinki", "[H]elsinki", "[Helsinki]" ja "Helsinki (Helsingfors)" would all be different municipalities in statistics and the search with the exact municipality name would only return the first one. This is why it is important to keep the actual data fields clean and tidy.
Notes fields
There are several notes fields in Kotka in different sections or levels of the specimen. For additional information that has no good place to enter in, use the notes field on the level that has those fields that the information is related to. For most general notes, use the field on the document level, in the Other section.
If you need to enter same kind of information repeatedly, and you think it is worth having its own field instead of a notes field, contact kotka(at)luomus.fi. Note that Kotka already has more than 150 fields, so adding new fields is most often not necessary.
- Document notes: notes that relate to information on the specimen/document level, or most general notes. There are also other notes fields on document level
- Notes about this edit: reasons for the edit or notes about it. Admins can also use this if they need to make some maintenance edits to the data, for example move data from one field to another.
- Transcriber's notes: any additional information the person entering the data may have regarding the data entry on transcription process. For example explanations for interpretations. Information not originally on the specimen.
- Nonpublic notes: For notes that should definitely be hidden from the public viewers (Kotka and laji.fi). Anyone with access to Kotka will see these notes.
- Collecting event/locality notes: notes related to the locality, collector, collection date etc. For coordinate notes, a separate field
- Coordinate notes: additional information about the coordinates.
- Unit notes: notes about the specimen/observation (unit), record parts, life stage, ring, etc. fields on the unit level. Separate fields for notes on the sex and age of the specimen
- Sex notes: e.g. who determined the sex and how, and any other notes about the sex of the specimen
- Age notes: e.g. who determined the age and how, and any other notes about the age of the specimen
- Identification notes: additional information about the identification, basis or reasoning etc.
- Type notes: notes about the type specimen information
- Preparation/sample notes: notes about the sample/preparation, information that has no other good place
Different sections in the data model
Basic & Other information (document level)
On the document level (beginning and end of web form), there are fields for information related to the whole specimen (all of its units). See Field documentation for more information on each field. Some things are highlighted here.
Condition field is for information on the specimen's possible damages, for example missing parts. If this field is empty, it means the specimen is OK.
Verification status is a multi-select field, meaning it is possible to choose several values. It is used to express any deficiencies or defects in the data in a systematic manner. This field can be used to kind of 'tag' the specimens you need to return to later.
Colllector's ID or LegID is a field for the field number (keruunumero) of the specimen. If the specimen has many collectors, you can write the name of the collector whose number it is as a prefix.
Additional IDs is a field for any other ID's the specimen might have, that do not have a separate field (BOLD, Genbank, Original catalogue number). Always include an explanatory prefix or header and use colon : to separate it from the identifier, for example "hyönteistietokanta:12345". Otherwise other people won't know what the identifier is about. Note that the same field is available also on the Sample-level, but there it is meant for IDs of the specific sample.
Acquisition date is used to enter the date or year when the specimen was acquired to the collections. This is very important for example from the perspective of the Nagoya protocol
Transcriber's notes is meant for notes the transcriber wants to save about the transcription, data entry or digitisation process, e.g. unclarities, explanations for interpretations. These are notes that are made by the transcriber and are not from the original data.
Tags are used for grouping the specimens together in various ways. You need to add a tag (using the Add tag form) first to use it for a specimen. More about tags
More about Specimen Identifiers
About Primary data location, see Secondary databelow.
Duplicates and separating specimens
If duplicate specimens are made and sent to other organizations, there are two ways to record this to Kotka. In both cases, each of the duplicates have to have unique identifiers (numbers).
A) Simple method: describe in the Duplicates field which duplicates have been sent and where, Preferably use IDs.
B) Exact method: write duplicate ID's to Separated to field, and create a gift/exchange transaction which lists all duplicates.
Separated to can also be used to enter the IDs of the new specimens that have been separated from this specimen, not duplicated. For example two specimens of different species on formerly one herbarium sheet with one identifier are separated to two new specimens on their own sheets with their own identifiers.
Separated from is used to enter the ID of the old specimen where the new specimens were separated from. For example the ID of the herbarium specimen that stays on the original sheet.
Collecting event and locality
The locality, collector, collection date, habitat, substrate, sampling method etc. all all related to the collecting event or gathering (keruutapahtuma) of the specimen. In Kotka, there is always one collecting event in a document.
If the collection date is an exact date, it is entered only to the Date begin field. If the exact date is not know, the period of time can be given using the Date begin and the Date end fields and the original information can be recorded to Date verbatim. For example the information "Jan-March 1975" is entered as such to Date verbatim and to Date begin 1.1.1975, and Date end 31.3.1975. If Date begin is unknown, use an early enough date so that the period covers the collection time, for example the date of birth of the collector or beginning of the century.
Sampling method is used to tell which (active) method of sampling was used to collect the specimen. This can be elaborated in the gathering level Notes field. If additional values are needed for the dropdown, contact the admins kotka(at)luomus.fi
Taxon associated with the specimen (seuralaislajit) are recorded either to associated taxa fields (apukentät) or directly as their own units (unit level information!). Type taxon names separated with a semicolon to the Associated observation taxa field, and Kotka makes units with the record type observation about these. Associated specimen taxa can be used in the same manner to create additional units of the type preserved specimen, but for taxon that are associated with the specimen. For example the actual specimen is a fish, which has a parasite on it. If you need to record other information in addition to the taxon names of the associated taxa, it may be easier to create units manually. Or use the assisting field to create the units and fill in more details later.
There are several fields for entering locality information. Write only one name per field to Country, Higher Geography, Biogeographical province, County and Municipality fields.
To Locality names you can write several place names in their basic format, from larger to smaller, separated with a comma. For example "Töölö, Hesperianpuisto". Also to Administrative province, you can enter several administrative areas, from larger to smaller, separated with a comma. For example "Etelä-Suomen lääni, Uusimaa"
Free-form descriptions of the place belong to the field Locality description. For example "500m from the church, northeast, south from the road".
Habitat description is a free-form or informal description of the habitat. Habitat classification if for formal, standardized classifications, e.g. the Finnish forest classification.
Alt in meters and Depth in meters are used to enter the altitude and depth where the specimen was collected, in meters. The value can be a decimal number or a range. Convert altitudes and depths in other units to meters and enter the original in verbatim locality if you wish. Altitude accept also negative values.
There is a Notes field on the gathering level, too. It can be used for any locality or gathering related notes, information that has no field of its own.
Coordinates and the map
There are several ways to enter coordinates. When digitizing old specimens, make sure that the original coordinates are always recorded as such (to the Verbatim coordinates field), even if they appear to be erroneous.
If the coordinates are already known (e.g. they are on the label or in a notebook), write them on Lat & Lon fields. If Coordinate system is known, select it from the dropdown list. You can also record the primary source of the coordinates, i.e. the place where collector got them, to the field Coordinate source. Also write the original coordinates to the Verbatim coordinates field.
If the original collector did not record coordinates, but they have been examined later based on the locality names (i.e. georeferenced), write the coordinates on Lat & Lon fields and select correct coordinate system. Then select the main source of the coordinates from Georeferencing source dropdown. This tells Kotka that the coordinates are not original but interpreted data. Both coordinate source and georeferencing source can not be filled for a specimen, you need to choose which one you use accordingly.
If you know how accurate the coordinates are, write the maximum error distance to Error radius in meters field. Also many GPS devices display the accuracy. You should not shorten any of the coordinates to tell their accuracy, but use the error radius field instead.
To revise, for the source of the original coordinates, use Coordinate source and for the source of coordinates acquired later by georeferencing, use Georeferencing source. Always remember to fill in Coordinate system and Error radius, if known.
When coordinates have been written to the Lat & Lon fields and coordinate system is selected, Kotka tries to show the place on the map. If the map icon is in a wrong place but coordinates and the system are correct, you can leave it as is; the coordinates are what matter.
Kotka shows following coordinate formats on map:
- WGS84 decimal coordinates. Southern latitudes and western longitudes have to be written as negative numbers (not with letters!) Use points (.) as decimal separator, though commas (,) are also supported. ETRS89 geographic coordinates (ETRS89 maantiet. koordinaatit) are practically similar to WGS84 and can be recorded as such. For example:
- Lat 60.123, Lon 23.123
- Lat 41.866184, Lon -87.616973 [western hemisphere]
- WGS84 degrees, minutes, seconds. Southern latitudes and western longitudes have to be written as negative numbers (not with letters!) Use ° or * as degrees symbol, ' as minutes symbol and " or '' as seconds symbols. You can add spaces between degrees, minutes and seconds, or leave them out. This format is not recommended for new specimens with exactly known locations, since it's more complicated than decimal degrees. For example:
- Lat 60° 11' 38.968", Lon 24° 36' 36.021"
- Lat 41° 51' 58.26", Lon -87° 37' 1.10" [western hemisphere]
- Finnish uniform grid coordinates (yhtenäiskoordinaatit, YKJ). Longitude has to be prefixed with number 3. Lat and Lon have to be of equal length. The southwestern corner of the grid will be shown. For example:
- Lat 668, Lon 338 [10 km accuracy]
- Lat 6681234, Lon 3384567 [1 m accuracy]
- ETRS-TM35FIN grid (ETRS-TM35FIN tasokoordinaatit)
- Lat 6675433, Lon 8367493 [note that Maanmittauslaitos omits the leading number 8 from longitude. You should omit in Kotka, too, as long as the coordinate system is selected accordingly. It is good to preserve the leading 8 in contexts where the system is not explicitly stated because these could be confused with uniform grid coordinates YKJ.
- These coordinates should only be used in full, 7-digit format and not in short form. If you wish to denote a grid, use YKJ coordinates instead. Kotka can't show the location on the map with these coordinates, if short form or decimals are used.
Following coordinates can also be recorded, but they are neither recommended nor (yet) shown on the map:
You can also select the place from the Kotka map, if you are georeferencing or recording your own specimens. When you click the map, the Lat, Lon & Coordinate system fields are automatically filled.
Specimen/Observation (units)
There can be one or more units per document. Each unit has one mandatory field, record type. Most often there is one unit of the type "Preserved specimen", and then other associated units of the type "Observation" (seuralaislajihavainnot).
Count is meant for the number of individuals in the specimen. This can be a number, a range, or a free-form description, e.g. "several". Then again "Abundance in the field" is where you enter the number of individuals in the field or describe the abundance at the site of collection.
A free-form description of the specimen/observation and information of the characteristics can be entered to Microscopic characters and Macroscopic characters. Note that there is also Identification notes on identification section, where you can enter additional information on the identification process, basis for identification or such.
Preparations field can be used to simply list preparates or preparations made from thew specimen (genital preparations etc.), if the separate Preparation/sample section is not used. It is highly recommended to use the Preparation/sample section, if you want to keep more detailed records of the preparations, for example when they were made, by whom, what material used, where stored etc. See below:Preparation/sample
Measurements are recorded so that you choose the "heading" or "prefix" for the measurement from the list and then type in the measurement number. You can enter the same measurement many times. On the web form, if you accidentally choose a measurement prefix that you do not want to enter, just leave it empty and it will be removed once you save the changes. It is easy for admins to add new measurement prefixes, contact the admins for this at kotka(at)luomus.fi
There is a Notes field on the Unit level, too, for additional information related to the fields in the section.
Identification(s)
In Kotka, taxon information has to be split into several fields. For example the taxon "Pinus cembra subsp. sibirica (DuTour) Kryl" would need to be recorded like this:
- Taxon rank: species
- Taxon name: Pinus cembra
- Taxon author: L.
- Infra rank: ssp
- Infra epithet: sibirica
- Infra author: (DuTour) Kryl
Enter for example species, genus, family or order level identifications to Taxon name. Epithets below species level belong to Infra epithet. It is often wise to keep the original taxon name in the Taxon verbatim field (with all possible errors and typos, additional information and notes). Sometimes it may not be easy to split complicated taxon names into separate fields like this to Kotka (there are also some validations), so the verbatim information is important to keep. There is no need to store the vernacular names in Kotka, as taxonomy is handled separately in the FinBIF taxonomic database. More information about the connection of Kotka to the taxonomy database: Handling taxonomy/Taksonomian käsittely.
Unclear or unofficial names can be entered in two ways, depending on the case (think about searchability and printing labels):
1) Enter the name to both taxon name and taxon verbatim (no linkage to taxon database)
2) Enter the most accurate certain taxon, for example genus, to taxon name and the original, unclear name to verbatim (linkage on genus level to taxon database if genus is found there)
Qualifiers, like cf., aff., sensu lato, sp. n. or such can be entered to the fields Genus qualifier and Species qualifier. There is no separate field for infra qualifiers (yet) and they can be entered into the identification notes and included in the taxon verbatim.
Det date can be an exact date or a year.
Identification section also has the field Identification notes for more information on the identification, its basis or such.
There can be several (or none) identifications per unit. If a specimen is re-identified or determined (määritetään uudelleen), always add a new identification instead of editing the existing and overwriting the information to that. If the taxon name changes but the identification is the same, there is no need to change the name to Kotka, because Kotka fetches the accepted taxon automatically from the FinBIF taxonomy database Master checklist (mostly for Finnish taxa so far). If there are several identifications, the "valid" identification is selected as follows:
- The identification that is marked as preferred (field Preferred identification)
- If none is marked as preferred, the newest identification based on det date (any date is newer than empty)
- If none contain det date, the topmost identification on the web form (on an Excel file, identification number 0 is preferred over 1)
In search, it is possible to filter only to the preferred identification of each specimen, by checking the filter checkbox "Only accepted"
On the web forms, Kotka gives taxon name suggestions from the FinBIF taxonomic database Master checklist and can automatically fill in the Taxon rank and Taxon author if a name is found and chosen from the list of suggestions. These suggestions or automatic fill-in is not available in Excel import.
Type
There is a separate section for recording type specimen information. The type of type for the specimen is chosen from the dropdown field. The option "Not a type" is used most often in cases where the specimen was mistaken for a type before, but actually is not one. Or in other situations, where it must to be highlighted that this is not a type. It is not necessary to choose this option for all non-type specimens.
The type taxon name can be entered entirely to to the Type name and Type author fields (there are less strict validation for taxon name entry in this section than in identification section). The name can also be split into several fields: species name, species author, subspecies name and subspecies author. This is a decision each collection can make themselves, bearing in mind the usability and searchability of the information, and printing it on labels.
Typifier is the name of the person who chose the specimen as a type.
In the field Verification it is possible to record whether is has been verified (based on literature for example) that this really is a type.
Preparation/sample
This is a relatively new section that was added to Kotka in spring 2019. It was developed mostly from the perspective of DNA and tissue samples and vertebrate subspecimens (osanäyte). If you have ideas for future development for different types of preparations/samples, contact kotka(at)luomus.fi.
Each unit can have one or more (or none) samples. If there are no samples taken or preparations made from the specimen, you can just ignore this section. There is one mandatory field in the preparation/sample section, meaning that if you fill in one of the fields in this section, you also need to choose the Preparation/sample type.
Within this section, there is a repeating element for information on the preparation of the sample. For example, a vertebrate part, e.g. a skull, may have been prepared by someone in 1980 using certain preparation process materials, and then another treatment made in 2005 by someone else using other materials.
Kotka automatically generates IDs for preparations/samples when they are recorded. The identifiers are based on the specimen identifier, and are of the format http://id.luomus.fi/LH.1#P1, with the last number being a running number for the samples. The identifier will become visible on the web form after successfully saving the document, and is visible in the document viewer and in Excel exports, too. Sample IDs are also generated when importing preparations/samples from Excel-sheets. If you need the IDs on your excel sheet before actually importing the data to Kotka, you can use the Generate ID's to Excel tool to create sample identifiers to the Excel.
There are some fields in this section that also appear in other sections in Kotka, but they have a different purpose:
- Measurements: here they are meant for measurements taken from the treated sample or preparation, dry skin for example. In the unit, record measurements taken from the "fresh", not yet prepared specimen.
- Events: maintenance and other types of events done to the sample here, events related to the whole specimen in the document level.
- Sample Genbank ID and Sample BOLD ID: ID of this specific DNA sample in Genbank or BOLD. There are the fields Genbank and BOLD also on the document level, and these can be used if there are no individual samples recorded otherwise. For BOLD, it is recommended to use the BOLD Sample ID.
- Preparation/sample status: The status of the sample, but for the status of the whole specimen, use the status field on the document level in the basic information section.
- Preparation/sample condition: Description of the condition of the sample, again for describing the condition of the whole specimen, use the condition field in the basic information section.
- Preparation/sample tags: Use the tags to group samples together and mark them. But to group or tag specimens, use the tags on the document level.
- Preparation/sample publication(s): if there are publications related particularly to a certain sample, list them here. If the whole specimen was used in the publication, use the field on the document level in the Other section.
- Preparation/sample additional sample IDs: any additional IDs the sample or preparation may have, that point to the specific sample and not to the whole specimen, e.g. labcodes or tissue numbers or such. There is a generate button on the web form for additional sample ids: write the prefix for the id, a colon and click the button and Kotka will give the next running number from the sequence for that prefix. It does not take into account whether the previous numbers have actually been used or not.
- Preparation/sample collection: the preparation or sample can belong to a different collection than the specimen it was taken from. For example, a bird specimen may belong to the taxonomic collection Aves, but a DNA sample taken from it belongs to a separate genomic resources collection. If a sample collection is not specified, Kotka uses the collection of the specimen in searches.
Publicity restrictions
This field can be used to hide information of single specimens from the public portal. The basis for concealment must be the Act on the openness of government activities (Julkisuuslaki). Note that you don't need to conceal specimens of Finnish sensitive species, as those are concealed automatically (for more information, see https://laji.fi/about/709 (in Finnish).
Publicity levels:
- Public: all information is public
- Protected: (has not been defined yet, so far functions the same way as private)
- Private: Locality information is coarsened to 100 km2, collection date is coarsened to 20 decades, most other information is hidden except for metadata (collection, tag, owner, editor etc.)
Relationships between specimens
Relationship field is used to record host/parasite or other types of relationships between specimens in Kotka. Relationship is on document level and the information entered to it is considered to belong to all the subspecimen units of the specimen (not observations). Relationship has predefined relationship types as prefixes. Choose a prefix first, and then after the colon, write either a taxon name or an identifier of another specimen. Prefixes can be added by admins if needed
- host
- parasite
- summerHost
- fallHost
- saprotroph
- observedOn
Examples:
- parasite:Parasiticus specius
- host:http://tun.fi/JAA.123
Several species in one specimen
If there are several different species in a specimen, these can be recorded in Kotka in a couple of different ways. An example of this kind of specimen is a bryophyte sample, that includes one "main species" and in addition pieces of other species.
A) Different species can be recorded as their own units with the record type "Preserved specimen". This way all the units can have their own identifications, abundance information etc., but same data on document level. Associated specimen taxa help field can be used for this.
B) Different species can be separated to individual specimens and recorded as separate specimens that get their own identifier and label. This way it is possible to record also differing information on document level, too. Separated from field can be used to record the identifier of the original specimen.
To record parasites, use the Relationship field. To record the substrate (e.g. tree species for a polypore) use either Relationship or Substrate.
Information about the time of data entry and person entering data
Part of this information is saved automatically. These fields include
- MZCreator (Created by, unique MA-identifier for the user, only one identifier per specimen)
- MZEditor (Edited by, unique MA-identifier for the user, only one identifier per specimen)
- MZDateCreated (Date created, format yyyy-mm-ddThh:mm:ss+0200)
- MZDateEdited (Date edited, format yyyy-mm-ddThh:mm:ss+0200)
Statistics on Kotka front page are based on these fields.
When importing old datasets from old systems to Kotka, information in these fields can be altered to include for example the original date when the data was created in the old system or the name of the person who originally entered or last edited the data there (instead of using the MA-identifier of the person importing the data to Kotka). If the original database does not have the date created stored, for example the last day of the previous year can be used to avoid the import from affecting the statistics of the current year, if desired. Date edited is however always saved automatically, and it is time datetime when the data was imported to Kotka. Altering this normally automatically saved data in import is only possible for admins, so contact kotka(at)luomus.fi if you need this to be done.
In Excel import, users can use two fields to manually enter the name of the person who transcribed the data and the date when the data was transcribed
- MYEditor (format "Lastname, Firstname", or name of the organisation/company, use ; to separate several names)
- MYEntered (format dd.mm.yyyy)
These are not used in statistics. These can be used for example in a situation, where several people have been digitising specimens to one table, but not all have MA-identifiers or are not working at the institution anymore. Also mass digitisation, specimens digitised by external companies etc.
Secondary data
Kotka is a primary system for primary data. But sometimes an organisation may need to keep records on specimens that are not part of its collections. There may be specimens that were loaned and identified and the data needs to be kept somewhere for e.g. research purposes. If the specimen data is in another system where it can't be accessed, Kotka can be used to store the data, but FinBIF also provides the Data bank (Aineistopankki) system for storing secondary data. See https://laji.fi/about/3977 (in Finnish).
The way to save this type of data in Kotka:
- Mark the data as secondary by filling in the Primary data location field. Write down where the primary copy of the data is stored. Filling in this field in Kotka does not prevent the data from being edited again in Kotka, so the user has the responsibility of the data (filling in the field used to prevent editing before). Always avoid making two version of the same data with some updates in the first and some updates in the other.
- Mark the specimen as hidden (Publicity restrictions: "private") if the data owner has not agreed to publishing the data.
- Save the specimen to the collection http://id.luomus.fi/HR.787 (Other collections) if the actual collection is not entered into Kotka as a separate collection.
- To the field Specimen location, record the name of the correct collection, if not entered into Kotka as a separate collection.
- If there are several specimens (>100), create a tag for them and in the tag information, describe why the specimens are entered into Kotka.
- Create labels for the specimens as you would for normal specimens.