Näytedatan tallennus
Englanninkielinen sivu: Entering specimen data

Tietojen syöttö
Kotkaan voidaan tallentaa dataa kahdella tapaa:
A) Webbilomakkeella
Webbilomaketallennus on helpoin tapa tallentaa muutaman näytteen tiedot. Eri näytetyypeille on eri lomakkeet: kasvinäytteille, eläinnäytteille, paleontologisille näytteille, puutarhojen kasvikannoille ja mikrobinäytteille. Lomakkeet ovat keskenään melko samanlaiset, mutta niillä on joitakin lomakekohtaisia kenttiä. Tietueen datatyyppi määräytyy käytettävän tallennuslomakkeen perusteella. Uuden, tyhjän tallennuslomakkeen löydät Kotkasta Specimens-valikosta, Add.... Kotka validoi datan tallennuksen yhteydessä. Lisää tietoa lomaketallennuksesta ja sen erityisyyksistä verrattuna Excel-importtiin löytyy alasivulta Specimen web forms
B) Excel-importilla
Datan tuonti Excel-importilla on nopeampi tapa suurempien datamäärien tallennukseen kerralla (kymmeniä tai satoja tai jopa 10 000 näytettä kerralla). Kotkasta saat ladattua tyhjän tallennuspohjan tarvitsemillasi sarakkeilla Tools-valikon alta löytyvät Excel generatorExcel generator- työkalun avulla. Täytä data taulukkoon, tunnisteiden ja muiden pakollisten tietojen kera (kts. alla). Importoi tiedosto Kotkaan Tools → Import. Kotka validoi datan ja näyttää esikatselun (tavallinen import). Jos validointi onnistui eikä datassa ole virheitä, voit tallentaa tiedot. Lisää tietoa Excel-templaateista ja importista sekä massamuokkauksista.
Pakolliset kentät ja validoinnit
Pakolliset kentät
Pakollisia kenttiä on vain muutamia, kaikki muut ovat vapaaehtoisia. Pakolliset tiedot ovat:
- Näytteen tunniste, Namespace ID ja Object ID -kentät. Lisää tietoa näytetunnisteista
- Kokoelma (collection), johon näyte kuuluu. Näyte kuuluu aina yhteen kokoelmaan. Kokoelmat taas liittyvät toisiinsa hierarkkisesti. Kokoelma määrittelee kenelle näyte kuuluu, missä sitä (karkeasti) säilytetään, kuka siitä vastaa jne. Lisää kokoelmista
- Näytteen omistaja-organisaatio (owner or record). Organisaatio, joka omistaa tietueen ja johon kuuluvat käyttäjät voivat editoida tietoja.
- Tietueen tyyppi (record type/basis). Yleensä tämä on preservedSpecimen, eli "tavallinen näyte". Tyyppi valitaan valikosta sallittujen arvojen listalta.
- Karkea paikkatieto: joko maa (country) tai maata laajempi alue (higher geography), esim. meri, mantere tai mantereen osa. Jos ei kerta kaikkiaan ole tiedossa mitään sijaintia keruulle, voidaan Higher geography -kenttään kirjata pakollisuuden kiertämiseksi "Earth"
Validoinnit
Kotkaan on määritelty joukko tarkistuksia, jotka tehdään tallennettavalle tiedolle. Validoinnit tehdään sekä lomaketallennuksessa että Excel-importissa. Lomakkeella varoitukset näytetään keltaisella pohjalla sivun yläosassa ja importissa ne tulevat omaan sarakkeeseensa esikatselussa. Validointijärjestelmässä on useita "sääntöjä" oikealle datalle. Näitä sääntöjä käytetään erilaisten virheiden löytämiseen datasta, kuten puuttuvien pakollisten tietojen, väärien sisältöjen ja väärien talelnnusformaattien löytämiseen .Tarkistustasoja on kaksi: virheelliset tiedot voivat antaa joko varoituksen tai virheen.
- Varoituksissa on kyse pienistä ongelmista, jotka eivät kuitenkaan estä tallennusta. Varoitus tulee esim. jos kerääjän nimi on annettu muussa muodossa kuin "Sukunimi, Etunimi."Varoitukset on hyvä käydä läpi, sillä ne auttavat pitämään datan siistimmässä kunnossa. Kun olet käynyt varoitukset läpi ja korjannut ne jotka on mahdollista korjata, voit jättää loput varoitukset huomiotta, jos data on sellaisenaan riittävä tarkoituksiisi.
- Virheet ovat suurempia ongelmia, jotka estävät tietojen tallennuksen. Kotka kertoo virheistä punaisella taustalla sivun ylälaidassa sekä importissa että lomakkeella. Importissa virheelliset solut korostetaan punaisella esikatselussa. Virheelliset kohdat on korjattava, ennen kuin tallentaminen on mahdollista. Virhe seuraa esim. pakollisen paikkatietokentän jättämisestä tyhjäksi.
Kaikki validoinnit on dokumentoitu kenttädokumentaatiossa, Mikäli kaipaat muutoksia (tiukennuksia tai höllennyksiä) tarkistuksiin, ota yhteyttä tiimisi Kotka-yhteyshenkilöön tai tietohallintotiimiin. Tarkistusten tarkoituksena on pitää tietojen laatu riittävän hyvänä häiritsemättä kuitenkaan tallennustyötä liikaa.
Hierarkinen datamalli
Näytetiedot tallennetaan Kotkaan hierakkisena rakenteena. Näyte (specimen) vastaa dokumnettia, jolla on Kotkassa aina yksi keruutapahtuma (gathering). Sen alla on yksi tai useampi havainto (specimen/observation tai unit) ja jokaiseen näistä voi liittyä nolla, yksi tai useita määrityksiä (Identification) ja tyyppinäytetietoja (Type). Jokaisella unitilla voi olla myös nollasta äärettömään preparaattitietoja (preparation/sample). Hierarkinen rakenne voi olla helpompi käsittää webbilomakkeella kuin Excel-tallennuspohjilla. Puutarhan kasvikannoilla voi lisäksi olla nollasta äärettömään puutarhasijoitusta (branch), joilla voi olla nolla tai enemmän tapahtumia (event).
Excel-lomakkeelle voi valita kutakin toistuvaa elementtiä 1-3 kappaletta. Suuremmat määrät pitää tallntaa käyttäen www-lomaketta.
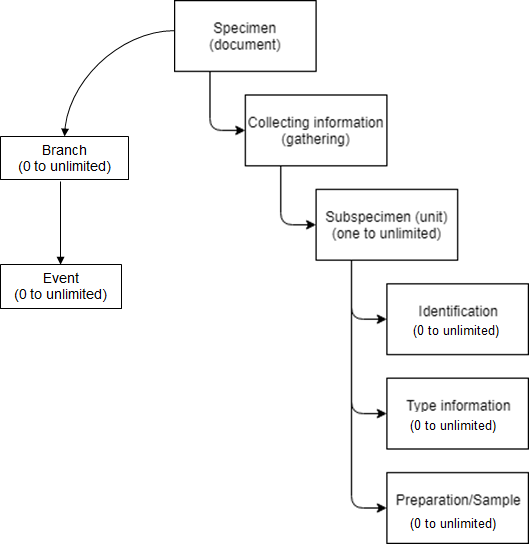
Kotkan käyttämä datamalli. Jokaisella näytteellä voi olla n määrä alanäytteitä (unit, esim. hyönteisiä purkissa) ja jokaisella voi olla n määrä määrityksiä, tyyppitietoja ja preparaatteja (morfologisia preparaatteja, DNA-eristyksiä, kudosnäytteitä yms.). Lisää tietoa kunkin osion kentistä ja datan syötöstä alla.
Yleisiä ohjeita datan syöttöön
Kotkassa on erityyppisiä kenttiä. Suuri osa kentistä on vapaatekstikenttiä. Joissain arvo pitää valita sallittujen arvojen listalta (pudotusvalikosta), osa on pudotusvalikoita joista voi valita useamman arvon ja joissakin täytyy valita ns prefix ja kirjoittaa sen perään sisältöä. Lisää arvoja voidaan tarvittaessa lisätä pudotusvalikoihin helposti. Ota yhteyttä kotka(ät)luomus.fi.
Osa kentistä on toistuvia, esimerkiksi kerääjän nimi (Leg) tai lisätunnisteet (additional IDs). Webbilomakkeella toisteisilla kentillä on vihreävalkoinen + -merkki niiden vieressä ja esim. jokainen kerääjänimi kirjataan lomakkeella omaan kenttäänsä. Excel-pohjassa toistuvat tiedot erotellaan puolipisteellä. Puolipistettä käytetään Excel-tallennuksessa erottimena myös kentissä, joihin voi valita useita arbvoja, kuten record parts.

Webbilomakkeita on mahdollista kustomoida niin, että osa kentistä piilotetaan. Lisää tietoa: Specimen web forms
Paikannimet voidaan kirjata minkä aikakauden kirjoitusasussa tahansa. Voidaan esim. valita käyttää keruuajankohdan kirjoitusasua tai nimeä. Ei ole tarpeen esimerkiksi muuttaa näytteellä olevaa Tammisaari-kuntanimeä Raaseporiksi (kuntaliitoksen johdosta), sillä tämä vähentää tiedon tarkkuutta. Maan nimille uusi maan nimi voi monesti olla tarkempi kuin vanha nimi, esim. Tsekkoslovakia vs. Tsekki. Paikannimet voidaan muuntaa nykyisiksi nimiksi tarvittaessa automaattisesti (ominaisuus ei vielä suunnitteilla).
Nimet kirjataan muodossa Sukunimi, Etunimi, mikäli koko nimi on tiedossa. Nimikirjaimet pyritään kirjaamaan samassa järjestyksessä. Useat nimet erotellaan puolipisteellä ei toistuvissa kentissä sekä lomakkeella että Excelissä, ja toisteisissa kentissä myös Excelissä.
Päivämäärät kirjataan muodossa pp.kk.vvvv, esim. 20.5.2015.
Desimaalierottimena käytetään pistettä, ei pilkkua.
Epävarmojen tietojen merkitseminen
Kotkassa on muutamia tapoja merkitä jokin tieto epävarmaksi. Kentät voidaan merkitä epävarmoiksi kirjaamalla kysmysmerkki kentän alkuun. Esim. "?Espoo". Niissä kentissä, joissa sallitaan vain ennalta määritellyt arvot (pudotuvalikolla), ei voida käyttää kysymysmerkkiä, joten valitaan niin laaja arvo, että se kattaa myös epävarmuuden.
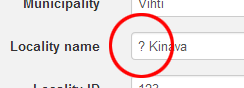
Koko näytteen tietojen epävarmuus merkitään valitsemalla arvo Needs verification kenttään Verification status. Tätä kenttää voidaan käyttää myös merkitsemään niitä näytteitä, jotka tarvitsevat esim. täydennystä tai georeferointia.
Qualifiereita voidaan käyttää epävarmuuden ilmaisemiseen määrityksessä, kts. määritykset alempana.
Verbatim-kentät ja tulkinnat dataan
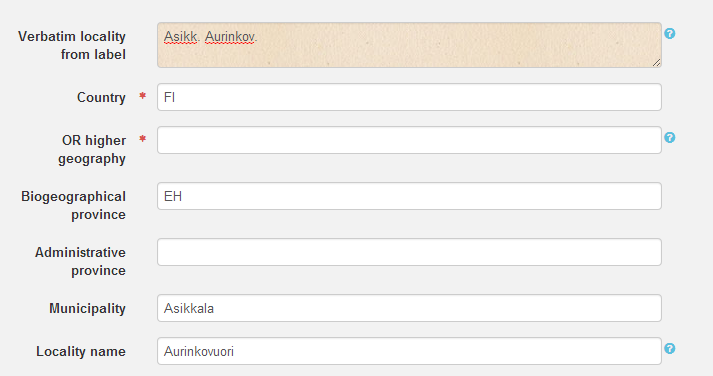
Vanhoja näytteitä tallennettaessa on tärkeätä säilyttää alkuperäinen data sellaisena, kuin se on etiketillä tai muussa alkuperäislähteessä, vaikka se vaikuttaisi virheelliseltä. Verbatim-kentät on tarkoitettu alkuperäisten tietojen tallennukseen. Tulkinnat voidaan sitten tallentaa varsinaisiin tallennuskenttiin. Tällä tavoin mitään dataa ei katoa tulkintaprosessissa ja on aina mahdollista palata takaisin alkuperäiseen dataan, mutta myös tulkittua dataan päästään hyödyntämään. Verbatim labels tarkoittaa alkuperäisiä etikettitietoja kaikkineen, muihin verbatim-kenttiin voi säilöä esim. aiempaan tietokantaan tallennettuja tietoja.
Esimerkiksi jos etiketillä on keruupaikkatietona "Asikk. Aurinkov.", kirjoita tämä Verbatim locality -kenttään. Sitten tulkitse tieto kunta-kenttään ja paikannimiin ("Asikkala" ja "Aurinkovuori").
Toinen tapa on ollut kirjata seka alkuperäinen että tulkittu data samaan kenttään ja erottaa tulkinnat hakasulkeilla (esim. "Asikk. [Asikkala], Aurinkov. [Aurinkovuori]"). Tätä ei kuitenkaan suositella, sillä tämänkaltaisen datan käyttäminen on vaikeaa koneelle. Merkintojä tulkinnoista saa kirjata vain verbatim- ja Notes-kenttiin, ei varsinaisiin datakenttiin. Myöskään ei ole syytä kirjoittaa samaa tietoa usealla kielellä samaan kenttään. Puuttuvat ja epäselvät kirjaimet voidaan merkitä kysymysmerkillä. Sanan katkaisua kysymysmerkillä kannattaa kuitenkin välttää, sillä ne hankaloittavat hakujen tekemistä, ellei sama tieto ole tulkittuna erilliseen kenttään.
Varsinaisiin tietokenttiin ei pidä tehdä merkintöjä tulkinnoista, eikä kirjata samaa asiaa eri kielillä. Näin toimiminen hankaloittaa hakujen ja tilastointien tekemistä huomattavasti. Esim. "Helsinki", "[H]elsinki", "[Helsinki]" ja "Helsinki (Helsingfors)" tulostuisivat tilastoihin neljänä eri kuntana, ja haku täsmällisellä kuntanimellä palauttaisi vain ensimmäisen näistä.
Muistiinpanokentät
Kotkassa on useita muistiinpanokenttiä (Notes) eri osioissa ja eri tasoilla tietuetta. Tieto, jolle ei ole varsinaista hyvää tallennuskenttää, tallennetaan notes kenttään, sillä tasolla jolla on kenttiä joihin lisätieto liittyy. Kaikkein yleisluonteisimmille muiistiinpanoille tai lisätiedoille käytetään dokumenttisason Notes-kenttää Other-otsakkeen alla.
Jos ilmenee tarve tallentaa jokin smanakaltaisena toistuva tieto usealle näytteelle, ja tieto saattaisi tarvita oman kentän muistiinpanokentän sijaan, voit olla yhteydessä ylläpitoon kotka(at)luomus.fi. Kannattaa kuitenkin huomioida että Kotkassa on jo yli 150 erilaista kenttää, joten uuden kentän luominen on harvoin tarpeellista.
Erilaiset muistiinpano- ja lisätietokentät:
- Document notes: lisätiedot liittyen tietoon dokumentti/specimen -tasolla, kaikkein yleisluontoisimmat muistiinpanot. Dokumenttitasolla on olemassa myös muita lisätietokenttiä.
- Notes about this edit: syitä muokkaukselle tai lisätietoje siitä. Ylläpito voi myös käyttää tätä kenttää ylläpitomuokkausten yhteydessä, kertomaan datan omistajalle miksi dataa on muokattu.
- Transcriber's notes: tiedon tallentajan lisätiedot datan tallenusta tai kirjausprosessia koskien. Esimerkiksi selostuksia tulkinnoille. Tiedolle, joka ei ole alunperin näytteessä.
- Nonpublic notes: lisätiedoille, jotka pitäisi piilottaa julkisesta näkymästä (Kotkan ja laji.fi:n julkiset näkymät). Kotkan sisällä muistiinpanot näkyvät kaikille, joilla on pääsy Kotkaan.
- Collecting event/locality notes: lisätietoja/muistiinpanoja koskien paikkaan, kerääjään, keruuajankohtaan ym. Koordinaatteja koskeville muistiinpanoille on erillinen kenttä.
- Coordinate notes: lisätietoa koordinaateista
- Unit notes: lisätietoa havainnosta (Specimen/observation = unit), esim. record parts, life stage, ring ym. kenttiin liittyen unit-tasolla. Ikää ja sukupuolta koskeville lisätiedoille on erilliset kentät.
- Sex notes: lisätietoja koskien sukupuolta, esim. kuka määritti sukupuolen ja miten.
- Age notes: lisätietoja koskien näytteen ikää, esim. kuka määritti iän ja miten.
- Identification notes: lisätietoja määrityksestä/tunnistuksesta, esim. määritysperusteet tms.
- Type notes: Lisätietoja liittyen tyyppinäytetietoihin
- Preparation/sample notes: Lisätietoja preparaatista, tietoa jolle ei ole muuta hyvää paikkaa preparation/sample -osiossa
Eri osiot datamallissa
Dokumenttitaso: Basic & other information
Dokumenttitasolla (webbilomakkeen alussa ja lopussa) on kenttiä tiedolle, joka koskee koko dokumenttia/specimeniä. Kenttädokumentaatiossa on tarkemmat ohjeet kullekin kentälle. Tässä on muutamia nostoja:
Kunto (Condition) -kenttään kirjataan näytteessä olevat vauriot, esim. puuttuvat osat. Tyhjä sisältö merkitsee että näyte on kunnossa.
Varmennus (Verification status) -kentässä ilmaistaan mahdolliset puutteet näytteen tiedoissa. Kenttään on mahdollista valita useita arvoja (ns. multi-select). Tätä kenttää voi ajatella ikään kuin tagina, jolla voi merkata näytteet joihin täytyy palata myöhemmin.
Keruunumero (maastonumero, kenttänumero) kirjataan kenttään Keruunumero (Collector's ID /LegID). Jos näytteellä on useita keruunumeroita, merkitään tähän niistä ensisijainen ja muut kenttään Muut tunnisteet. Jos näytteellä on useita kerääjiä, voit kirjoittaa kerääjän nimen keruunumeron eteen, jotta tiedetään kenen keruunumerosta on kyse.
Muut tunnisteet (Additional ID's) -kenttään kirjataan näytteellä olevat muut tunnistenumerot ja vastaavat, joille ei ole omaa erillistä kenttää (vrt. BOLD, Genbank, Original catalogue number). Kirjoita numeron alkuun lähde kaksoispisteellä eroteltuna, esimerkiksi "hyönteistietokanta:12345". Muuten tiedon käyttäjät eivät tiedä, mistä tunnisteesta on kyse. Huomaa, että sama kenttä on myös sample-tasolla mutta se on tarkoitettu nimenomaan samplea koskeville lisätunnisteille.
Saantiajankohta (Acquisition date) -kenttään kirjataan päivämäärä tai vuosi, jolloin näyte on saatu kokoelmiin. Tämä tieto on erittäin tärkeä esim. Nagoyan pöytäkirjan näkökulmasta.
Tallentajan muistiinpanot (Transcriber's notes) on tarkoitettu tallentajan lisätiedoille koskien tallennusta, kirjaamista tai digitointiprosessia, esim. epäselvyydet tai selostukset tulkinnoille. Nämä ovat muistiinpanoja, jotka tallentaja luo, eivätkä ne ole peräisin alkuperäisestä datasta.
Tagit tai avainsanat ovat Kotkassa tapa merkitä näytteitä kuuluvaksi yhteen eri tavoin. Tagi tulee ensin lisätä käyttäen Add tag -lomaketta, jonka jälkeen sitä voi käyttää näytteelle. Lisää tageista.
Lisää näytetunnisteista
Kenttä Primary data location, kts. Sekundääridata alla.
Duplikaattien ja näytteiden erotuksen hallinta
Jos näyte duplikoidaan ja lähteteään muihin organisaatioihin, tieto duplikaateista on mahdollista tallentaa Kotkaan kahdella tavalla. Molemmissa tapauksissa kaikilla duplikaateilla tulee olla uniikit tunnisteet.
A) yksinkertaisempi tapa: kuvataan duplikaattikentässä (Duplicates) mitä duplikaatteja on lähetetty ja minne, mieluiten antamalla näytetunnisteet.
B) täsmällisempi tapa: kirjataan duplikaattien tunnisteet Separated to -kenttään, ja kirjataan lahjoitus/vaihto -transaktio jossa listataan kaikki duplikaatit.
Separated to -kenttää voidaan myös käyttää myös tilanteessa, jossa näytteestä erotetaan osia uudeksi näytteeksi, ei duplikoida. Tällöin kenttään kirjataan uusien näytteiden tunnisteet. Esimerkki: kaksi eri lajin kasvia samalla herbaarioarkilla yhdellä tunnisteella erotetaan kahdeksi uudeksi näytteeksi eri arkeille, ja ne saavat omat tunniseet.
Separated from -kenttään kirjataan vanhan näytteen tunniste, se josta uudet näytteet erotettiin. Esim. sen näytteen tunniste, joka jää alkuperäiselle herbaarioarkille alkuperäisellä tunnisteella.
Keruutapahtuman taso: Collecting event & locality
Keruupaikka, kerääjä, keruuajankohta, habitaatti, kasvualusta, keruumenetelmä jne. liittyvät kaikki näytteen keruutapahtumaan (collectiing event / gathering). Kotkassa on aina yksi keruutapahtuma per dokumentti.
Jos keruupäivä on tarkka päiväys, tallennetaan se Alkupäivä -kenttään (Date begin). Jos tarkka keruupäivämäärä ei ole tiedossa, merkitään se päivämäärävälinä Alkupäivään ja Loppupäivään (Date end). ja alkuperäinen tieto voidaan tallentaa Date verbatim -kenttään. Esim. "tammi-maaliskuu vuonna 2000" kirjataan sellaisenaan verbatimiin ja merkitään päivämäärävälinä date begin 1.1.2000 ja date end 31.3.2000. Jos alkupäivämäärä ei ole tiedossa, merkitään se niin varhaiseksi että päivämääräväli varmasti kattaa keruuajan, esimerkiksi kerääjän syntymäpäiväksi tai vuosisadan alkuun.
Keruumenetelmä (Sampling method) -kentässä valitaan millä menetelmällä näyte on kerätty. Tätä voi tarkentaa Notes-kentässä. Jos pudotusvalikkoon tarvitaan lisää arvoja, kannattaa olla yhteydessä ylläpitoon kotka(at)luomus.fi
Seuralaislajit kirjataan joko puolipisteellä eroteltuina Seuralaislajit (Associated taxa) -apukenttiin tai suoraan omina uniteinaan. Seuralaislajihavainnot voidaan kirjata puolipisteellä erotettuna Associated observation taxa -kenttään, jolloin Kotka tekee näistä automaattisesti unitit, joiden tyyppi on havainto (observation). Associated specimen taxa -kenttää voidaan käyttää samaan tapaan näytteessä olevien seuralaislajien kirjaamiseksi.Esim. päänäyte on kala, jolla on loinen. Jos on tarpeen tallentaa seuralaislajista muutakin tietoa kuin lajinimi, voi olla helpompaa luoda erilliset unitit manuaalisesti apukenttien käyttämisen sijaan. Tai voi käyttää apukenttiä alkuun ja täydentää muut tiedot unitiin myöhemmin.
Paikannimien kirjaamiseen on useita kenttiä. Maa (country), Laajempi maantieteellinen alue (higher geography), Eliömaakunta (Biogeographical province), county ja Kunta (municipality) -kenttiin kirjataan vain yksi nimi kuhunkin.
Paikannimet (Locality names) -kenttään voi kirjoittaa useita paikannimiä perusmuodossaan, pilkulla eroteltuina, suurimmasta pienempään. Esim. "Töölö, Herperianpuisto". Myös hallinnollinen alue (Administrative province) -kenttään voi kirjata useita hallinnollisia alueita suuremmasta pienempään, pilkulla erotettuna. Esim. "Etelä-Suomen Lääni, Uusimaa"
Vapaamuotoiset kuvaukset sijainnista kirjataan Paikan vapaamuotoinen kuvaus (Locality description) -kenttään. Esim. "500 m kirkosta kaakkoon, Palolammentien eteläpuolella"
Habitaatin kuvaus (Habitat description) on vapaamuotoinen kuvaus elinpaikasta. Habitaatin luokkaan (Habitat class) kirjataan virallinen luokitus, esim. "OMT".
Korkeus (Alt) ja Syvyys (Depth) kenttiin kirjataan näytteen keruukorkeus- ja syvyys metreinä. Arvo voi olla myös desimaaliluku tai vaihteluväli, esim. 1200-1500. Mittayksikköä ei kirjata. Muissa yksiköissä ilmoitetut korkeudet ja syvyydet tulee muuntaa metreiksi ja alkuperäisen arvon voi halutessaan tallentaa verbatim locality -kenttään Korkeus hyväksyy myös negatiivisia arvoja.
Keruutpahtuman tasolla on myös kenttä muistiinpanoille. Tähän kirjataan keruuseen liittyvät lisätiedot, joille ei ole omaa paikkaa.
Koordinaatit ja kartta
Koordinaattien kirjaamiseen on useita tapoja. Kun digitoidaan vanhoja näytteitä, alkuperäiset koordinaatit kannattaa tallentaa aina myös sellaisenaan Verbatim coordinates -kenttään, vaikka ne vaikuttaisivatkin virheellisiltä.
Jos koordinaatit tiedetään (esim. etiketiltä tai muistikirjasta): koordinaatit kirjataan Lat ja Lon -kenttiin. Jos koordinaattijärjestelmä on tiedossa, valitaan se Coordinate system -kenttään pudotusvalikosta. Koordinaattien lähde (jos tiedossa) kirjataan Coordinate source -kenttään. Alkuperäiset koordinaatit kirjataan Coordinates verbatim -kenttään.
Jos koordinaatteja ei ole alunperin tiedossa, mutta ne selvitetään myöhemmin paikannimien perusteella eli georeferoidaan: Koordinaatit kirjataan Lat ja Lon -kenttiin ja koordinaattijärjestelmä valitaan Coordinate system-kenttään. Koordinaattien lähde valitaan Georeferencing source -kenttään. Tämä kertoo sen, että koordinaatit eivät ole osa alkuperäistä dataa vaan ne on saatu georeferoimalla myöhemmin. Sekä Coordinate source että georeferencing source -kenttiä ei voi täyttää yhtä aikaa, vaan tulee valita oikea kenttä tilanteen mukaan.
Jos koordinaattien tarkkuus on tiedossa, kirjataan virhesäde metreissä kenttään Error radius in meters. Monet GPS-laitteet myös näyttävät tarkkuuden. Mitään koordinaatteja ei tulisi lyhentää tarkkuuden ilmaisemiseksi, vaan käyttää virhesäteen kenttää. Vain YKJ-koordinaatteja voidaan lyhentää ruudun ilmaisemiseksi eri tarkkuudella.
Kertauksena: alkuperäisten koordinaattien lähteelle käytetään Coordinate source -kenttää, ja myöhemmin hankittujen koordinaattien lähteelle georeferencing source -kenttää. Koordinaattijärjestelmä ja virhesäde tallennetaan aina, jos ne on tiedossa.
Kun koordinaatit on tallennettu Lat ja Lon -kenttiin ja koordinaattijärjestelmä on annettu, Kotka yrittää näyttää sijainnin kartalla. Jos karttapiste menee väärään kohtaan mutta koordinaatit ja järjestelmä ovat oikein, annetaan olla niin: koordinaatit merkitsevät.
Kotka näyttää seuraavat koordinaatit kartalla:
- WGS84 desimaaliasteet. Eteläiset leveysasteet ja läntiset pituuspiirit kirjataan negatiivisina (ei käytetä kirjaimia W ja S!). Käytetään pistettä desimaalierottimena (joskin pilkku hyväksytään myös). ETRS89 maantieteelliset koordinaatit ovat kläytännössä hyvin lähellä WGS84 -koordinaatteja ja voidaan kirjata sellaisina. Esim.
- Lat 60.123, Lon 23.123
- Lat 41.866184, Lon -87.616973 [läntinen pallonpuolisko]
- WGS84 asteet, minuutit ja sekunnit. Eteläiset leveydet ja läntiset pituudet kirjataan negatiivisina (Ei käytetä kirjaimia W ja S). Asteen symbolina käytetään merkkejä ° tai *, minuutin symbolina ', ja " tai '' as sekunnin symbolina. Asteiden, minuuttien ja sekuntien väleissä voi olla välilyönnit tai ne voi jättää pois. Tätä koordinaattimuotoa ei suositella käytettäväksi uusille näytteille tarkoille paikoille, koska se on desimaaliasteita mutkikkaampi. Esim.
- Lat 60° 11' 38.968", Lon 24° 36' 36.021"
- Lat 41° 51' 58.26", Lon -87° 37' 1.10" [läntinen pallonpuolisko]
- Yhtenäiskoordinaatit YKJ. Longitudin edessä käytetään ns. etukolmosta. Latitudin ja longitudin tulee olla saman pituiset. Kartalla näytetään ruudun lounaiskulma. Esim.
- Lat 668, Lon 338 [10 km accuracy]
- Lat 6681234, Lon 3384567 [1 m accuracy]
Myös seuraavia koordinaatteja voidaan tallentaa Kotkaan, mutta niitä ei suositella käytettäväksi eikä Kotka osaa ainakaan vielä näyttää niitä kartalla:
- ETRS-TM35FIN tasokoordinaatit
- Esim. Lat 6675433, Lon 8367493 [huomaa että Maanmittauslaitos jättää longitudista ensimmäisen kahdeksikon pois. Se jätetään pois myös Kotkassa, kunhan koordinaattijärjestelmä on valittu oikein. Sellaisissa konteksteissa, joissa koordinaattijärjestelmää ei ilmoiteta selkeästi, on hyvä säästää ensimmäinen kahdeksikko pituuspiirissä, jotta koordinaatit eivät mene sekaisin YKJ-koordinaattien kanssa. Näitä koordinaatteja tulisi aina käyttää täydessä 7-numeroisessa pituudessaan, eikä lyhentää kuten YKJ-koordinaatteja.
- Desimaaliasteet, järjestelmä ei tunnettu. Nämä voivat näyttää WGS84-koordinaateilta, mutta sijainti voi heittää paljonkin riippuen järjestelmästä
- Asteet, minuutit, sekunnit, järjestelmä ei tunnettu.
Webbilomaketallennuksessa paikan voi valita myös Kotkan kartalta, jolloin Kotka täydentää automaattisesti latitudin, longitudin ja koordinaattijärjestelmän.
Havainnot: specimens/observation (unit)
Yhdessä dokumentissa voi olla yksi tai useampi unit. Jokaisessa unitissa on yksi pakollinen kenttä: tietueen tyyppi (Record type). Useimmiten dokumentissa on yksi unit, joka on tyyppiä "Preserved specimen", jonka ohella on toisia uniteja, jotka ovat havaintoja (seuralaislajihavainnot).
Lukumäärä (Count) -kenttään kirjataan näytteen yksilöiden tms. määrä vapaamuotoisesti. Tämä voi olla luku tai myös vapaamuotoinen kuvaus, esim. "several". Lajin runsaus keruupaikalla merkitään erilliseen kenttään Runsaus maastossa (Abundance in the field).
Näytteen vapaamuotoisen kuvauksen ja tietoa tuntomerkeistä voi kirjata kenttiin Mikroskooppiset tuntomerkit ja Makroskooppiset tuntomerkit (Microscopic characters, Macroscopic characters). Huom. määritysosiossa on myös identification notes -kenttä, johon voi tallentaa määritysperusteita ym.
Preparaatit (preparations) -kenttää voidaan käyttää yksinkertaiseen preparaattien listaamiseen, jos erillistä preparaattiosiota ei käytetä. On varsin suositeltavaa käyttää erillistä preparaarttiosiota, jos preparaateista halutaan pitää yksityiskohtaisemmin kirjaa, esim. valmistaja, valmistusjaankohta, valmistuksen menetelmät ym. Kts. alla Preparaatit: Preparation/sample
Mittatietoja tallennetaan niin, että ensin valitaan mitalle ns. otsikko tai prefix listalta, ja sen perään kirjoitetaan mittaluku. Saman mitan voi syöttää useaan kertaan. Jos webbilomakkeella valitsee vahingossa väärän mittaotsikon jota ei halua käyttää, sen voi vain jättää tyhjäksi ja se poistuu kun näytteen tiedot tallentaa. Ylläpito pystyy lisäämään uusia mittaotsikoita, kotka(at)luomus.fi
Myös unit-tasolla on kenttä muistiinpanoille ja lisätiedoille koskien saman tason kentissä olevaa tietoa.
Määritykset: identification
Kotkassa määrityksen taksonitieto pilkotaan useisiin kenttiin (toisin kuin esim. Taxoneditorissa). Esim. taksoni "Pinus cembra subsp. sibirica (DuTour) Kryl" tallennettaisiin näin:
- Taxon rank: species
- Taxon name: Pinus cembra
- Taxon author: L.
- Infra rank: ssp
- Infra epithet: sibirica
- Infra author: (DuTour) Kryl
Taksonin nimi -kenttään kirjataan esim. laji-, suku-, heimo- ja lahkotason määritykset. Lajinsisäiset epiteetit kirjataan infra epithet -kenttään. On suositeltavaa säilyttää alkuperäinen taksonin nimi Taxon verbatim -kentässä, mukaanlukien kaikki virheet, muistiinpanot ym. Taksonin nimeä ei ole aina helppo pillkoa Kotkan eri tallennuskenttiin yksikäsitteisesti, mistä syystä alkuperäisen tiedon säilyttäminen on kannattavaa. Taksonin kansankielisiä nimiä ei ole tarpeen säästää Kotkassa, koska taksonomia hallinnoidaan erillisessä Taksonitietokannassa. Lisätietoa Kotkan ja taksonitietokannan kytkennöistä: Handling taxonomy
Epäselvän tai epävirallisen nimen voi tallentaa kahdella tapaa (vrt. haettavuus ja etikettien tulostus):
A) Nimi kirjataan sekä taxon name että taxon verbatim -kenttiin (ei kytkentää taksonitietokantaan)
B) Tarkin mahdollinen taksonin nimi, esim. suku tai heimo, kirjataan taxon name -kenttään ja alkuperäinen nimi taxon verbatim -kenttään. (kytkentö taksonitietokantaan sukutasolla, jos suku löytyy tietokannasta)
Taksonin tarkenteita (qualifier, esim. cf., aff., sensu lato, sp. n.) voidaan kirjata kenttiin Genus qualifier ja Sepcies qualifier. Lajinisisäisten epiteettien tarkenteille ei ole omaa kenttäänsä, mutta ko. tiedon voi kirjata määrityksen muistiinpanoihin ja taxon verbatim -kenttään.
Määrityspäivä (Det date) voi olla tarkka päivä tai vuosi (pv.kk.vvvv tai vvvv)
Määritysosiossa on myös oma kenttänsä määritykseen liittyville lisätiedoille, esim. määritysperusteille ym., identification notes.
Yhdellä unitilla voi olla useita (tai ei yhtään) määrityksiä. Jos näyte määritetään uudelleen, lisätään aina uusi määritys (identification -elementti) eikä kirjoiteta tietoja aiemman määrityksen päälle. Jos taksonin nimi muuttuu mutta määritys pysyy samana, ei ole tarpeen muuttaa nimeä Kotkaan, koska Kotka hakee automaattisesti hyväksytyn taksonin (accepted taxon) nimen taksonitietokannasta, Lajitietokeskuksen master checklistiltä (sisältää enimmäkseen suomalaisia lajeja). Jos näytteekkä on useita määrityksiä, voimassa oleva määritys määräytyy Kotkassa seuraavasti:
- Se määritys, joka on merkitty suositelluksi (Preferred identification = yes)
- Jos suositeltua määritystä ei ole valittu, uusin määritys määrityspäivän mukaisesti on suositeltu määritys (mikä tahansa määrityspäivä on logiikassa uudempi kuin tyhjä)
- Jos millään määrityksellä ei ole määrityspäivää, ylin määritys webilomakkeella/pienimmän indeksinumeron omaava määritys Excel-taulukossa on suositeltu määritys.
Haussa on mahdollista suodattaa tuloksista pois muut määritykset ja näyttää vain suositeltu valitsemalla suodattimista "Only accepted"
Webbilomakkeilla Kotka antaa ehdotuksia taksonien nimille Lajitietokeskuksen taksonitietokannan master checklistiltä. Se täydentää automaattisesti määrityksen taksonomisen tason ja auktorin, jos nimi löytyy ja valitaan listalta. Automaattiset ehdotukset ja täydennykset eivät ole käytettävissä Excel-tallennuksessa.
Tyyppinäytteet: Type
Kotkassa on erillinen osio tyyppinäytetietojen kirjaamiseen. Tyypin tyyppi valitaan pudotusvalikosta (Type of type). Vaihtoehto "Not a type" käytetään useimmiten tapauksissa, jossa näytettä luultiin erehdyksessä tyyppinäytteeksi, mutta myöhemmin on todettu ettei se olekaan sitä. Voidaan käyttää myös muissa tilanteissa, joissa on tarpeen korostaa, että kyseessä ei ole tyyppinäyte. Tätä ei kuitenkaan ole tarpeen valita kaikille ei-tyyppinäytteille.
Tyypin taksoninimi voidaan kirjata kokonaisuudessaan Type name ja Type author -kenttiin (tyyppiosiossa on vähemmän validointeja taksonin nimelle kuin määritysosiossa). Nimi voidaan myös valita jakaa erikseen kenttiin: species name, species author, subspecies name ja subspecies author. Valinnan kirjaustavan välillä voidaan tehdä kussakin kokoelmassa itse, ottaen huomioon tiedon haettavuuden ja esim. tulostamisen etiketeille.
Tyypittelijä (Typifier) on sen henkilön nimi, joka valitsi näytteen tyypiksi.
Varmistus-kentässä (Verification) voidaan kertoa, onko varmistettu että kyseessä todella on tyyppiyksilö, esim. kirjallisuuden perusteella.
Preparaatit: Preparation/sample
Tämä on kohtuullisen uusi osio Kotkassa: se lisättiin keväällä 2019. Osio kehitettiin enimmäkseen DNA- ja kudosnäytteiden sekä selkärankaisten osanäytteiden näkökulmasta. Osiota voidaan kehittää edelleen tarpeiden ilmetessä, ota yhteyttä kotka(at)luomus.fi.
Jokaisella unitilla voi olla yksi tai useampi (tai ei yhtään) preparaattia. Jos näytteestä ei ole yhtään preparaattia, tämän osion voi vain jättää täyttämättä ja huomiotta. Osiossa on yksi pakollinen kenttä, joka pitää täyttää, jos täyttää osion muita kenttiä: Preparation/sample type.
Preparaattiosiossa on sisällä toisteinen elementti preparaatin valmistustietojen täyttämiselle. Esim. selkärankaisnäytteen osa, kuten kallo, voi olla jonkun valmistama vuonna 1980 joillain menetelmillä ja materiaaleilla, ja joku toinen voi olla tehnyt samalle kallolle toisen käsittelyn toisilla materiaaleilla vuonna 2005.
Kotka generoi preparaateille automaattisesti tunnisteet, kun preparaatteja tallennetaan. Preparaattien tunnisteet perustuvat näytteen tunnisteeseen ja ovat muotoa http://id.luomus.fi/LH.1#P1, jossa viimeinen numero on juokseva numero preparaateille. Preparaatin tunniste tulee näkyville webbilomakkeelle, kun dokumentti tallennetaan onnistuneesti ensimmäisen kerran. Preparaatin tunniste on näkyvillä myös dokumentin tietojen katselussa ja Excel-exporteilla. Preparaateille generoidaan tunnisteet myös Excel-importissa. Jos preparaatit tarvitsevat tunnisteet jo enenn kuin varsinainen data tallennetaan Kotkaan, voidaan käyttää Generate IDs to Excel -työkalua tunnisteiden generoimiseen.
Osiossa on joitakin kenttiä, jotka on käytössä myös muualla Kotkassa, mutta niillä on tässä eri tarkoitus:
- Measurements: tässä osiossa on tarkoitus tallentaa mittoja, jotka on otettu preparoidusta näytteestä, esim. kuivasta nahkasta. Unit-tason mittatiedot on tarkoitettu "tuoreen" näytteen mitoille.
- Events: preparaatille tehdyt huoltotoimet ym., koko dokumenttia koskevat huoltotoimet dokumenttitasolle.
- Sample Genbank ID jaSample BOLD ID: tämän nimenomaisen DNA-näytteen tunnisteet Geenipankissa tai BOLD:ssa. Dokumenttitason vastaaviin kenttiin voidaan tallentaa nämä tunnisteet, jos preparaattitietoja ei tallenneta muutoin erikseen. BOLD- tunnisteessa on suositeltavaa käyttää BOLD Sample ID -tunnistetta.
- Preparation/sample status: Preparaatin tila. Koko dokumentin tilan ilmaisemiseen on vastaava kenttä dokumenttitasolla.
- Preparation/sample condition: Preparaatin kunto. Koko dokumentin kunnon kuvaamiseen on kenttä dokumenttitasolla.
- Preparation/sample tags: Tageja voidaan käyttää preperaattien ryhmittelyyn ja merkitsemiseen kuuluvaksi yhteen. Jälleen koko dokumentin merkitsemiseen käytetään dokumenttitason vastaavaa kenttää.
- Preparation/sample publication(s): juuri kyseiseen preparaattiin liittyvät julkaisut voidaan listata tässä. Jos julkaisussa käytettiin tai viitataan koko dokumenttiin, käytetään dokumenttitason vastaavaa kenttää.
- Preparation/sample additional sample IDs: kenttään tallennetaan preparaatin lisätunnisteet, jotka viittaavat nimenomaan kyseiseen preparaattiin, esim. labrakoodi, kudosnumero ym. Webbilomakkeella on käytettävissä generointinappi: kirjoita id:n otsikko ja kaksoispiste, paina generate -nappia, jolloin Kotka antaa seuraavan juoksevan numeron kyseisen otsikon sekvenssistä. Huom. Työkalu ei huomioi onko edellinen numero oikeasti käytetty vai ei, ts. onko sillä tallennettu tietoa, se vain ottaa generate -napin painallukset huomioon. Additional IDs on myös dokumenttitasolla, koko dokumenttia koskeville lisätunnisteille.
- Preparation/sample collection: Preparaatti voi kuulua eri kokoelmaan, kuin mihin sen ns. emonäyte kuuluu. Esim. lintunäyte voi kuulua taksnomisesti järjestetyissä selkärankaiskokoelmissa kokoelmaan "Aves", mutta siitö otettu DNA-näyte (preparaatti) kuuluu erilliseen genomikokoelmaan. Jos preparaatin kokoelmaa ei määritellä, katsoaan sen Kotkassa kuuluvan dokumentin kokoelmaan esim. hauissa.
Salaukset
Publicity restrictions: Tämän kentän avulla voi salata yksittäisten näytteiden tietoja julkisuudelta. Salauksen on perustuttava julkisuuslakiin.Huomaa, että kotimaisia snesitiivisten lajien näytteitä ei tarvitse salata manuaalisesti, vaan ne salataan taksonitietokannan kautta automaattisesti. Lisää tietoa sensitiivisistä lajeista ja salauksista: https://laji.fi/about/709
Salaustasot:
- Public: kaikki tiedot ovat julkisia
- Protected: (ei vielä määritelty, toimii toistaiseksi kuten private)
- Private: Sijainti karkeistetaan 100 km2 tarkkuuteen, keruupäivä karkeistetaan kahden vuosikymmenen tarkkuuteen ja suurin osa muusta tiedosta piilotetaan (paitsi metatiedot kokoelma, tag, omistaja, tallentaja, muokkaaja jne.)
Näytteiden väliset suhteet
Kotkaan voi kirjata näytteiden välisiä suhteita Suhteet (Relationships) -kentän avulla. Kenttä on dokumenttitasolla ja suhdetieto tukitaan liittyväks kaikkiin näytteen alanäytteisiin. Havaintoihin sitä ei katsota liittyväksi.
Kenttään kirjataan ensin suhteen tyyppi. Näille käytetään vakioituja arvoja, joita voidaan tarvittaessa luoda lisää.
Arvot (12/2015):
- host
- parasite
- summerHost
- fallHost
- saprotroph
- observedOn
Tämän jälkeen kirjataan kaksoispisteellä eroteltuna joko taksonin nimi tai toisen näytteen tunniste. Esim.:
- parasite:Parasiticus specius
- host:http://tun.fi/JAA.123
Useita lajeja samassa näytteessä
Jos näytteellä on useita lajeja, voidaan tämä kirjata kotkaan muutamalla eri tavalla. Esimerkki tällaisesta näytteestä on esim. sammalnäyte, jossa todetaan olevan "päälajin" lisäksi paloja muistakin sammallajeista.
A) Kirjaamalla eri lajit omiksi alanäytteikseen (unit). Tällöin jokaiselle voidaan kirjata omia määrityksiä, runsaustietoja jne., mutta yhteiset yleistiedot. "Päälaji" kirjataan omana alanäytteenään, muut voi kirjata puolipisteellä eroteltuina Associated specimen taxa -kenttään, jolloin Kotka pilkkoo ne automaattisesti alanäytteiksi. (Tämä on yleensä helpompi kuin B-tapa.)
B) Kirjaamalla eri lajit omina näytteinään Kotkaan ja antamalla jokaiselle oma tunniste(etiketti). Tällöin jokaiseen voidaan liittää omia geenipankki- ja BOLD-tunnisteita, kudosnäytetietoja jne. Erotettu näytteestä (Separated from specimen) -kenttää voi käyttää merkitsemään mistä näytteestä uudet näytteet on erotettu.
Loiset voidaan tallentaa käyttäen Relationship -kenttää.
Kasvualustan laji (esim. käävällä puulaji) voidaan kirjata Relationship -kentällä, tai vapaatekstinä Substrate-kenttään.
Tietoja tallennusajankohdasta ja tallentajasta
Kun tiedot tallennetaan Kotkaan, tallentuu niiden yhteyteen automaattisesti tieto tallentajasta ja tallennusajankohdasta.
- MZCreator (Created by, käyttäjän uniikki MA-tunniste, vain yksi tunniste per dokumentti)
- MZEditor (Edited by, käyttäjän uniikki MA-tunniste, vain yksi tunniste per dokumentti)
- MZDateCreated (Date created, muoto yyyy-mm-ddThh:mm:ss+0200)
- MZDateEdited (Date edited, muoto yyyy-mm-ddThh:mm:ss+0200)
Tilastoinnit tuotetaan näiden tietojen perusteella.
Vanhoja aineistoja Kotkaan vietäessä voidaan näitä kenttiä muokata sisältämään esim. alkuperäinen luontipäivä vanhasta järjestelmästä tai alkuperäinen tallentaja tai muokkaaja (sen sijaan että tallentuisi Kotkaan importoivan henkilön MA-tunniste/nimi.). Jos alkuperäisessä tietokannassa ei ole luontipäivää, voidaan käyttää esim. edellisen vuoden viimeistä päivää, jotta tiedot eivät vaikuta kuluvan vuoden tilastoihin, jos niin halutaan. Editointipäivä tallentuu kuitenkin aina automaattisesti Kotkaan importoinnin ajankohdan mukaan. Näiden tavallisesti automaattisesti tallentuvien tietojen muokkaus on mahdollista vain ylläpitäjille, joten ota yhteyttä kotka(at)luomus.fi jos tarvitset näihin muokkausta.
Excel-importissa on lisäksi käytettävissä kaksi kenttää, joihin voi manuaalisesti tallentaa tietojen kirjaajan nimen ja kirjauspäivän:
- MYEditor (muodossa "Sukunimi, Etunimi", tai organisaation nimi, käytä puolipistettä nimien erottamiseen)
- MYEntered (muodossa dd.mm.yyyy)
Näitä ei käytetä tilastoissa. Näitä voidaan käyttää esim. tilanteessa, jossa useat henkilöt ovat kirjanneet tietoja yhteen ja samaan taulukkoon, mutta yksi henkiölö importoi datan tai kaikilla ei ole MA-tunnisteita. Myös esim. massadigitointi ja ulkoinen digitointi.
Sekundääridata
Kotka on tarkoitettu primaaritiedolle. Joskus organisaatiossa kirjataan muistiin tietoja siellä tutkimuskäytössä tai määrittettävänä olevista näytteistä, vaikka nämä eivät kuuluisi sen kokoelmiin. Tietoja voidaan tarvita esimerkiksi tutkimustyössä. Tällaisten näytteiden tiedot voidaan tallentaa Kotkaan, mikäli niitä ei ole tallennettu jonkin vakiintuneen organisaation (esim. toisen museon tai Lajitietokeskuksen) tietojärjestelmään. Nykyisin Lajitietokeskuksella on Aineistopankki sekundaaridatan tallennusta varten. https://laji.fi/about/3977
Sekundaaridatan tallennus Kotkaan:
- Näyte merkitään sekundääridataksi, täyttämällä Primary data location -kenttään sen organisaation tai tietokannan nimi, jossa primaaridataa säilytetään. Tämän kentän täyttäminen ei enää estä datan muokkausta Kotkassa, vaan on käyttäjän vastuulla pitää huolta datasta. On aina viimeiseen asti vältettävä tekemästä datasta kahta versiota, jossa yhtäällä on toiset tiedot ja toisaalle tehdään toiset päivitykset.
- Näyte merkitään salatuksi (Publicity restrictions: private), ellei julkaisuun ole saatu omistajan nimenomaista lupaa
- Näyte liitetään kokoelmaan http://id.luomus.fi/HR.787 (Other collections), ellei todellisen kokoelman tietoja ole kirjattu kokoelmaluetteloon
- Näytteen sijaintitiedoksi (specimen location) merkitään toisen kokoelman nimi (esim. "Coll Matti Meikäläinen"), jos sitä ei kirjata kokoelmaluetteloon
- Jos näytteitä on lukuisia (>100), liitetään ne tagiin, jonka tiedoissa kerrotaan miksi näytteet ovat sekundääridataa ja miksi ne on kirjattu Kotkaan
- Näyte etiketöidään kuten museon oma näyte
Merkintä sekundääridataksi tehdään Excel-importissa luomalla sarake otsikolla MYPrimaryDataLocation. Tähän kenttään kirjataan vapaamuotoisesti missä primääridata sijaitsee. Esim. toisen kokoelman nimi. Tätä ei ole dokumentoitu muualla, koska sekundääridataa on syytä tallettaa vain erikoitilanteissa.