2.1 Data preprocessing
Typically all types of computational analysis require preprocessing of data before the analysis can be run.
Textual data
Data that is already in a textual format usually needs some preprocessing for computational methods to be able to process it correctly. The phases are dependent on the language of the data.
Lemmatization / stemming is a process of reducing the words into their base or dictionary form, by removing e.g. inflectional endings. It is especially needed for agglutinative languages that typically inflect words, such as Finnish, Korean, or Sumerian.
the boy's cars are different colors
the boy car be differ color
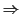
However, these two differ somewhat:
Stemming often refers to a crude heuristic process that chops off the ends of words to reduce the input word to its base correctly most of the time. This often includes the removal of derivational affixes.
Lemmatization refers to a proper process of reducing words to their dictionary form, using a vocabulary and morphological analysis of words. The aim is to remove inflectional endings only and to thus to get the base or dictionary form of a word, known as the lemma . E.g. for the word saw, stemming might return s, whereas lemmatization would give either see or saw depending on whether the token was used as a verb or a noun in its linguistic context (see Manning et al., 2008).
Stop words are words that carry little semantic meaning in a text, such as (and, but, on, to, in...) and also auxiliary verbs. Including them in the analysis when using computational text mining methods that do not understand sentence structure typically causes confusion in the models. Therefore, they are typically removed before running the analysis. Stop word lists in different languages are embedded in several analysis packages (e.g. NLTK), or they can be searched for online.
Keyword-based filtering can be used to filter units of data that are related to a topic of interest defined by the research problem. For example, including only posts that use a specific hashtag, mention specific actors etc.
Other file formats (pdf, images, videos)
Analyzing non-textual formats typically requires transforming them into a textual format in some way. That means e.g. ripping text from pdf-files or presenting images as fingerprints.
Useful non-coding tools for data wrangling and exploratory analysis
- Tableau
- Software for data wrangling and analysis
- Free academic license available
- Open Refine
- Powerful tool for data wrangling
- Url Harvester
- Tool for extracting urls from text